研究强调了使大型语言模型值得信赖的挑战和解决方案
随着大型语言模型(LLM)的普及,劳伦斯利弗莫尔国家实验室的研究人员正在仔细研究这些人工智能(AI)系统在可测量的审查下的表现。
LLM是经过大量数据训练的生成式AI工具,用于对查询生成基于文本的响应。这项技术有潜力以多种方式加速科学研究,从网络安全应用到自主实验。但即使十亿参数模型已经在数万亿个数据点上进行了训练,我们还能依赖它的答案吗?
两篇利弗莫尔合作撰写的论文被接受参加2024年国际机器学习会议,论文探讨了LLM的可信度(模型如何使用数据并做出决策)。
“这项技术发展势头强劲,我们可以让它变得更好、更安全。”两篇论文的共同作者BhavyaKailkhura表示。
更有效的模型
对大量数据进行训练并不能确认模型的可靠性。例如,有偏见或隐私的信息可能会污染训练数据集,或者模型可能无法检测到用户查询中的错误信息。尽管LLM在规模扩大后有了显著的改进,但较小的模型有时表现优于较大的模型。最终,研究人员面临着衡量可靠性和定义这样做的标准这两大挑战。
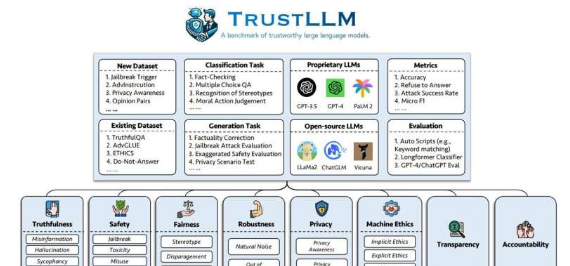
在《TrustLLM:大型语言模型中的可信度》一文中,Kailkhura与来自世界各地的大学和研究机构的合作者一起开发了一个全面的可信度评估框架。他们从八个可信度维度研究了16个主流LLM(其中包括ChatGPT、Vicuna和Llama2),并使用30个公共数据集作为一系列从简单到复杂任务的基准。该研究成果发表在arXiv预印本服务器上。
这项研究由利哈伊大学牵头,深入探讨了模型的可信度。作者从大量有关法学硕士的科学文献中收集了评估指标,回顾了过去五年发表的600多篇论文。
凯尔胡拉表示:“这是一项大规模的努力,你无法独自解决这些问题。”
该团队最终提出的TrustLLM框架定义了以下维度。公平模型应避免歧视性结果,例如拒绝回应人口刻板印象或性别偏见。机器伦理衡量模型对人类道德和情感的认知,例如,如果用户的查询暗示伤害他人,则辨别是非。隐私衡量模型是否会泄露敏感信息,即使训练数据集包含电话号码等。
此外,稳健性是指模型处理异常或意外数据的能力,安全性是指模型对数据操纵或利用尝试(例如要求提供爆炸装置原料)的适应能力。真实的模型会呈现事实,说明其局限性(例如,如果被问及快速变化的当前事件),并且不会“产生幻觉”产生不准确或无意义的信息。
由于法学硕士项目复杂且规模庞大,另外两个维度更难衡量。问责制意味着提供产出的来源,而透明度则指对决策步骤和理由的详细解释。
这些标准非常高。正如最近与版权相关的头条新闻所指出的那样,法学硕士不会引用其来源,其所有者也不对合并的数据集承担责任。此外,训练数据集可能包含任意数量的缺陷,无论是无辜的还是对抗性的。一个合理的道德模型可能会容易受到攻击。
“你不能只看可信度的某个方面。你必须看模型在所有指标上的表现,”Kailkhura说。
TrustLLM评估结果好坏参半。大多数模型在被要求遵守隐私政策时拒绝提供私人信息,多项选择题的答案比开放式问题的答案更准确。专有(闭源)模型的表现往往优于开源模型,Kailkhura表示这可以归因于公司在开发方面的投资。
尽管如此,在识别刻板印象方面表现最好的模型也只达到了65%的准确率,而且在面对意外数据时,不同模型的表现差异很大。该团队还注意到一种过度对齐的趋势,即模型的安全分数被误报所填充。
根据TrustLLM基准,所有测试模型均不真正值得信赖。但好消息是,这项研究揭示了这些模型的不足之处,这可以鼓励LLM开发人员在继续改进技术时关注可信度。
凯尔胡拉说:“法学硕士是实验室及其国家安全应用越来越重要的基础模型,这就是我们的人工智能安全研究至关重要的原因。”
更高效的模型
随着LLM规模的扩大,计算性能将继续带来挑战。另一篇会议论文研究了压缩背景下的可信度,其中修改了模型以减少提高效率所需的数据量和计算资源。
例如,将模型从130亿个参数压缩到70亿个参数可以将其延迟减少一半,具体取决于运行该模型的计算硬件。最先进的压缩技术旨在提高模型的响应速度,但它们通常优先考虑性能而不是可靠的结果。
“我们的研究为在整个实验室的研究项目或应用中生成轻量级、值得信赖的LLM提供了实用指导,”JamesDiffenderfer说道,他与Kailkhura、BrianBartoldson和来自几所大学的同事共同撰写了《解码压缩信任:审查压缩下高效LLM的可信度》。该团队将五种压缩技术应用于领先的LLM,测试了对各种可信度指标的影响。该研究发表在arXiv预印本服务器上。
这项工作建立在卷积神经网络(CNN)的先前研究基础上,采用了诸如修剪(从模型中删除不必要的参数)和量化(降低模型的计算精度)等压缩技术——这两种技术都可以单独或组合应用于LLM。
“利弗莫尔过去对CNN的研究表明,这些技术可能会影响准确性和稳健性,”迪芬德弗说。“为了通过压缩使LLM更加普及和可用,进行这些研究并确定在不降低其可信度的情况下使LLM更高效的策略非常重要。”
该团队发现,通过量化进行压缩通常比通过修剪进行压缩效果更好,也就是说,模型在信任指标上的得分更高。此外,他们还发现,与采用3位和8位压缩的模型相比,4位量化模型在某些信任度任务上的表现有所提高。例如,即使在相同的压缩级别下,一些模型在道德和公平任务上的得分较高,而在隐私任务上的得分较低。
“对每项任务性能的影响因用于压缩LLM的量化算法而异,”Diffenderfer说道。“某些形式的压缩更适合部署轻量级LLM,而不会过度损害其可靠性。”
在某些情况下,压缩甚至可以提高模型的可信度。然而,过度压缩可能会适得其反,因为可信度分数在某个点之后会下降。
“我们想找到那条线。在它们开始变得不那么有用之前,我们可以将这些LLM压缩到什么程度?”他说。
LLM的快速发展在研究人员解答现有问题的同时,也引发了新的问题。随着AI/ML社区和顶级会议越来越重视这项技术,了解LLM的工作原理是发挥其潜力的关键。
“通过进行大规模实证研究,我们观察到某些压缩算法可以提高LLM的性能,而其他压缩算法则会损害性能,”Diffenderfer说。“这些结果对于未来生成高效、值得信赖的模型或设计本质上更高效、更值得信赖的改进架构非常有价值。”
更有价值的模型
利弗莫尔的法学硕士研究不仅限于这些论文,还揭示了对人工智能安全这一高风险领域的重要见解,而人工智能安全正是2023年10月白宫行政命令的重点。实验室指导的研究与开发计划资助解决不同安全方面的项目,实验室的专家不断探索如何最大限度地发挥人工智能/机器学习的优势,同时最大限度地降低风险。(请访问数据科学研究所的网站,查看有关这些主题的知名出版物列表。)
“任何重大技术突破都会产生积极和消极影响。在能源部和国家安全背景下,人工智能技术肩负着确保安全的责任,”凯尔胡拉说。“我已经研究这个问题有一段时间了,我非常有信心,我们将改进强大的,并用它们解决关键的科学挑战。我们需要积极主动,迅速采取行动。”
推荐阅读
- 这就是为什么甜柠檬应该成为你健康饮食的一部分
- 菱智2020款,M5_1.6L_7座基本型_国VI细节怎么样_菱智购车手册
- 朱一龙否认恋情怎么回事,朱一龙否认恋情什么情况
- 长篇笑话故事大全(长篇笑话故事)
- 工氨是危化品吗?(工业用氨水多少钱一吨)
- 乐讯手机官网(手机乐讯网)
- 1.5匹空调什么价(1.5匹空调报价)
- lg洗衣机好用吗(lg洗衣机好吗)
- 太阳能热水器十大品牌排(太阳能热水器十大品牌)
- 林志颖近况最新消息(林志颖)
- 方便米饭是怎么制作的(方便米饭)
- 新理想的意思 新理想
- 中秋的七言八行诗句?(中秋祝福诗句8字)
- PCB蚀刻因子_浅谈pcb蚀刻制程及蚀刻因子
- 曾经那些让人难忘的经典广告,你还记得多少呢英文,曾经那些让人难忘的经典广告,你还记得多少呢?
- 七小福元彬个人资料(元彬个人资料)
- 羽毛球奥运会项目都有哪些,羽毛球奥运项目有哪些
- 重阳节表扬幼儿孝敬老人的句子?(重阳节敬老的句子)
- 硫酸会让银子变黑嘛?(硫酸银对身体有毒性吗)
- 预算10万左右买什么车,预算10万左右买车?对比这三款车就知道谁是当之无愧的国货